Resiliency at Scale for Web Service
An engineering manager’s perspective on inheriting and transforming a critical core service.

This is an overview of my team’s experience inheriting a critical core service, and enabling the service to horizontally scale and support read requests upwards of 10,000 requests per second (RPS) with an average response time of less than 500 milliseconds.
“Schema-Registry” is a Java service used to create and manage Experience Data Model (XDM). XDM is a publicly documented specification used to describe the structure of data in a consistent and reusable way.
At a high level, an XDM schema provides an abstract definition of a real-world object (such as a person) and outlines what data should be included in each instance of that object (such as first name, last name, birthday, and so on).
The first step in onboarding a customer to Adobe Experience Platform (AEP), is the creation of a schema. Once a schema is created, it is used as a blueprint to validate the data in a wide array of workflows such as segmentation, activation and so on.
The Challenges
The following is a list of items that made horizontal scaling challenging:
Complex Composition Model
An XDM object is stored as a hierarchical structure using JSON (JavaScript Object Notation) with $allof and $ref notations to extend it.
A schema is usually composed of a behavior, a class and one or more field groups, data types or descriptors.
See Figure 1 below for details:

In MongoDB, XDM objects are stored as JSON documents with URL references to other JSON documents.
This is useful when updating, as per the example in Figure 1.
The field group “Phone number” can be updated without triggering a rebuild of schema A. This is essential given the “Phone number” field group can be used in hundreds of schemas.
The challenges with the composition model are:
- Schema Composition can be slow and CPU intensive. For example, a profile schema is built by merging N schemas and can take up to a minute to de-reference and merge all the field paths.
- Schema JSON can have n-levels in a hierarchy structure. For example, a schema is composed of field group “A.” The field group “A” can be composed of field group “B” and field group “C.” The Field group “B” can be composed of field group “E” and so on. Multi-level embedding can make schema de-referencing slow.
Knowledge Gaps
The service is a monolith supporting a wide array of functions such as:
- Schema Validation.
- Lookup/List a Schema/Field group/Data types/Descriptors.
- Merge a set of Schema.
- Search Schema/Field group/Data types/Descriptors based on regular expressions.
- Export and Import of Schema.
- Field level access controls.
The development team also owned CI/CD, MongoDB Infrastructure, and quality.
Overall, the cognitive load on the development team was high and most of the developers focused on a subset of features, since context switching is difficult and often slows down production.
Exponential Increase in GET Request Traffic
Over the years Adobe Experience Platform has experienced phenomenal growth.
We onboarded new customers and internally we added new features and functionality to the Platform.
The schema registry service is the core service that validates data structures. Fortunately, Adobe engineers are used to thinking about running services “at scale” and making design decisions that support rapid growth.
For example, the registry service elegantly handles over ten times the amount of traffic used in the original estimations.

Thundering Herd Problem
We realized that — based on the complexity and volume of GET requests — we could run into a thundering herd situation.
Some of the contributing factors were as follows:
- The Read-through cache was a collection in the Database, and had performance impact when running complex queries on the database.
- The data was lazy-loaded in the Cache, which was not effective in scenarios where spark jobs created thousands of clusters and connected simultaneously to fetch schema metadata.
- There were slow queries in the system that took more than a minute to process and were CPU intensive. Example, queries with regex pattern, queries with IN clause with 25 or more documents, queries with multi document merge and so on.
A “Thundering Herd” problem would look like Figure 2:
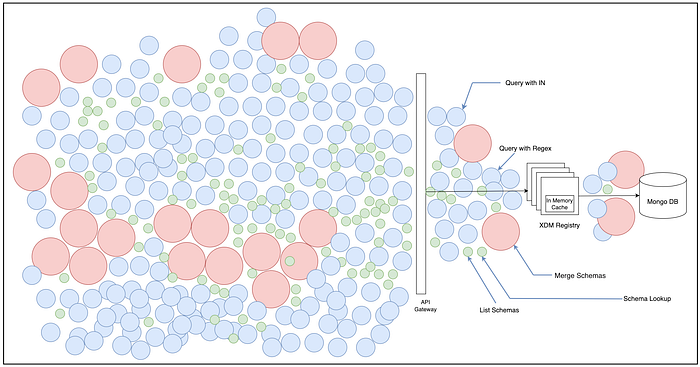
We also hypothesized that:
- The service was on the critical path for Platform, and every service dependent on it had retries in place and would cause an exponential increase in traffic.
- During restarts of the service for CI/CD, the in-memory cache was flushed. All requests went to the database to fetch the data causing spikes in database CPU usage.
- The complex composition model and query pattern can cause MongoDB instances to remain at 100% CPU usage for a long duration.
In summary, the service can experience thread starvation. In a scenario where all the threads in the service are waiting for MongoDB to complete processing the queries, the service could get into a restart loop as follows:
- The Kubernetes Pod starts. Multiple connections are made to the database.
- MongoDB database is slow due to an increase in the number of queries. The resource (CPU, memory, thread-pool) usage is high on the MongoDB servers, and it is slow to respond to queries.
- The health check on Kubernetes will terminate the Pod due to slow response time. A new set of Pods are initialized by Kubernetes, which makes new connections to the database.
- The downstream services will get an error response and their retries will kick in, causing an increase in the number of GET requests.
The Solution
XDM Schema registry was one of the earliest services developed, it existed even before Platform. The service was built for a different scale and purpose. Our goal was to modernize the service and make it a first-class service.
We split the solutions into the following groups:
Guardrails
We added guardrails to the system to mitigate known issues:
- We created throttling strategies to shape API access by smoothing spikes in traffic.
- For example, a blanket throttle of 300 RPS will ensure that — during a thundering herd scenario — the spike in traffic doesn’t go beyond 300 RPS. The API Gateway would respond with HTTP Status Code 429 Too Many Requests. Given schema registry had downstream services with varying demands, we put in a blanket throttle and service level throttling.
- Optimized MongoDB queries. We created a rubric of slow queries with their explain plan and converted most of the COLLSCAN (collection scan) to IXSCAN (index scan) by adding indexes. We also added guardrails to queries with IN to allow up to 5 documents.
- We also determined some of the queries were using collation but we did not have index with collation. Adding the collated indexes exponentially improved the performance on collated queries.
People
Schema registry had gone through multiple revisions and the team had gone through several personnel changes. It was initially written in JavaScript and later ported to Java. The team currently managing it had a big gap in the tribal knowledge that comes with tenure.
Some of the focus areas were:
- Building a knowledge base across the product line through knowledge transfer sessions.
- Adding more collaboration across the team for feature development, to avoid knowledge silos.
- Hands-on group debugging sessions to deep dive into the code.
- MongoDB learning plan to bridge the gap in database infrastructure.
Process
We also made changes to process, such as:
- Controlling release to production.
- Instead of migrating over 100% of the incoming requests to the new Kubernetes pods, we adopted blue/green deployment to shift traffic to the new pods 10% at a time.
- Improving monitoring and alerting.
- Improving code and test coverage. The code coverage requirement is set to greater than 90% for all newly contributed code.
- A bug bash before every release.
- Following a “relaxed” version of TDD (Test Driven Development) methodology for development, where every feature requires design discussion and test plan review before the first line of code is written.
Architecture
Single point of failure (SPOF)
The schema registry service was a singular service supporting schema creations, build, validation, and retrieval. It lacked a fallback mechanism when there were availability issues on MongoDB.
We narrowed down on one unique feature of XDM. Our database size was small, and the complexity in the system was in the read RPS and schema build. One way to mitigate the SPOF was to build a new service that would store pre-built schemas.
The new service marked in blue in Figure 3, consists of:
- Full cache build to refresh the cache.
- Continuous cache update to keep the source of truth and cache in sync.
- An SLA of 5 minutes when an update happens in the source of truth and when it propagates to the cache.
- The new service stores the composed schemas in memory. There is no database call when a read request is made to the service giving us better performance.
- Horizontal scale can be accomplished by adding new Kubernetes pods to the deployment.
- An internal messaging system was built to keep the S3 persistent store in sync with cache builder and the metadata service.
- The new service endpoint has the same signature as the schema registry. The integration in the dependent service would be a mere swap of the client URL.

Restarts and Cache
When a restart occurs, the following events happen:
- The in-memory cache is flushed. This turned out to be inconsequential since the TTLs (time to live) on this cache was < 30 seconds. This cache served use cases where there was big influx of duplicate requests when Spark batch jobs start.
- The cache collection in MongoDB which served as the lazy-loaded cache was invalidated during the global XDM releases. The Global XDM is a library consisting of standardized out of the box classes/field groups/datatypes/schemas etc., Rebuilding the cache was expensive after global release since a standard component can be used across 100s of schemas.
One of the scenarios that can cause the thundering herd problem was the cache collection invalidation. Every subsequent call after invalidation was a schema composition which was CPU intensive in MongoDB.
To resolve this, we decided instead of invalidating the cache, we would do the global release 24 hours prior to the actual release so that the TTL (time to live) on the cache collection would take care of keeping the rows up to date. We had to get buy-in from all the stakeholders before we could proceed, but the followings helped with the decision:
- Global schema releases were infrequent.
- Global schema releases were backward compatible.
- The 24-hour latency between publishing and availability in production was acceptable.
Database
Another bottleneck was the database infrastructure. We were running the MongoDB community edition on Azure VMs (Virtual Machines). This setup lacked tooling and insights.
We relied on Splunk and New Relic to retrieve Query Plans, MongoDB replica set lag, health stats, and so on.
We had to log into each VM (Virtual Machine) and update it using the command line.
And we had hundreds of VMs!
Also, the sharded collections in MongoDB made horizontal scaling non-trivial. Adding a shard would require the data to be migrated across shards by the MongoDB balancer.
We determined that given the size of our data, vertical scaling on the database would be more efficient than horizontal scaling during high demand periods. We went from a multi-shard to a single shard for all our collections.
We are also migrating our database to MongoDB Atlas. We completed the pre-prod environments last month and saw a significant improvement in our query performance when we added recommendation from the Atlas Profiler and Performance Advisor.
We are also investigating moving our open-ended queries with regex to MongoDB Atlas Search.
Conclusion
In summary, when onboarding to a new service, my first step as an Engineering manager was to accelerate the team’s learning curve by reviewing and deep diving into the existing system.
We were able to identify and make multiple improvements to the release process, architecture, and technology stack.
All of this gave our customers an uninterrupted, wonderful experience when using Adobe Experience Platform, and platform-native applications.

