Trip Report: Summer ISO C++ Standards Meeting
A recap of June’s standards meeting in Varna, Bulgaria.

The June 2023 ISO/IEC C++ Varna meeting was my first in-person standards meeting since COVID.
I almost forgot the heightened efficiency of week-long, face-to-face, distraction-free meetings. I’m so done with Zoom for this kind of work!
This post covers the highlights of my trip.
There’s the sad outcome of Joe Jevnik’s and my std::simd Types Should be Regular paper, but the happier outcome of inplace_vector.
I’ll also discuss my concerns for a few proposals that made it into the working paper: std::function_ref, std::copyable_function, and some std::bind_{front|back} updates.
Finally, I’ll touch on some notable functionality that was added at this meeting (static_assert messages, RCU, Hazard Pointers, .visit for std::variant, and multi-dimensional array slicing).
Let’s get the unpleasant stuff over with first…
std::simd’s conflict with regularity
Standardizing SIMD types has been a marathon, but merging this feature is now in sight.
Matthias Kretz deserves a lot of credit; it takes exceptional technical ability and fortitude to standardize a feature of this scale. As much as I want to like it, however, I have beef with one element of its design.
My concern centers on the == operator in C++.
Before this proposal, a == b always indicated whether an object a has the same value as object b. The idea of using the same spelling (e.g. ==) for an operation (e.g. equality) across distinct types is the basis of generic programming in C++. Uniform syntax for a notional semantics allows us to write a single, efficient find function that works on both std::vector<int> and std::list<std::string>.
Equality and its uniform spelling are fundamental. They are part of the operation set of Stepanov’s so-called regular types. A == operator that computes something other than value equality is as confusing and inconsistent as an assignment operator that does not assign.
If ever there were a convention worth upholding, regularity is it.
The std::simd proposal breaks this convention: Instead of computing equality of two SIMD vectors, its == operator computes equality of corresponding lanes and returns a mask. It is easy to see how someone would arrive at this design since binary operators like + work lane-wise (which is consistent with the mathematical meaning of + for tensors).
However, lane-wise == is inconsistent with == for tensors, conflicts with the C++ standard library, the C++ language (e.g. =default for ==), and developer expectations (auto a = b; assert(a == b)).
Joe Jevnik and I wrote a paper and I delivered a presentation at the Varna meeting highlighting our concern. Unfortunately, we failed to convince enough people in the room that std::simd shouldn’t break consistency with the rest of the standard.
I’m left quite concerned that Stepanov’s original vision for a catalog of highly generic algorithms has lost its importance in WG21. This feels like a shift to me.
On the upside, those who are transitioning from C++ to Rust can rest assured that Rust’s standard SIMD library made the right decision by spelling lane-based equality as simd_eq and leaving == with its value equality semantics.
I also haven’t 100% given up on std::simd for C++: I’m considering writing a SIMD concepts for generic programming paper which motivates and mandates consistency with Regular.
std::inplace_vector
std::inplace_vector is like a std::vector except all its storage is within the object itself instead of separately allocated, giving it a fixed capacity. inplace_vector‘s avoidance of heap allocations is especially useful in embedded and real-time systems.
In the lead-up to the Varna meeting, Timur Doumler invited me to participate in some design discussions for the inplace_vector proposal. The primary question was which variants of push_back were needed.
Here’s where we ended up:
// Appends x and returns a reference to the new element.
//
// - Throws: std::bad_alloc if size()==capacity()
T& push_back(const value_type& x);
// Appends x if size()<capacity() and returns a pointer to the new
// element; returns nullptr otherwise.
T* try_push_back(const T& x);
// Appends x and returns a reference to the new element.
//
// - Precondition: size()<capacity()
T& unchecked_push_back(const T& x);push_back’s interface mimics that of std::vector so that it can be used as a drop-in replacement. The T& return type is the one difference. A T& return type was actually added to std::vector’s push_back in a prior standard draft, but was removed because it would cause an ABI break.
We figured we might as well make std::inplace_vector’s push_back have the interface we want since there aren’t any ABI compatibility isn’t a concern here.
When “out of capacity” situations are common, try_push_back is preferred: it avoids accidental exception propagation and its calls can conveniently be put in conditionals. It also helps those who cannot use C++ exceptions due to, e.g., real-time constraints.
unchecked_push_back was added for those with the “need for speed”. If you call it when capacity is unavailable, you get undefined behavior.
Given all recent focus on safety, do we really need another unsafe operation like this? It is easy to exploit an invalid unchecked_push_back call on an inplace_vector sitting on the stack. Concern is appropriate.
Also, is there a substantial speed benefit? With branch prediction, the bounds check may be free most of the time. During the Varna meeting, I built a quick and dirty microbenchmark to find out. Here are the two test cases (you can see the actual code here):
// f is a function that does nothing. It is defined in a separate
// translation unit so its calls won't be inlined.
void f( std::inplace_vector<int, 1000000>* );
// T1: fill the vector with data and then call f
for (size_t i=0; i<N; ++i)
v.push_back(data[i]); // or unchecked_push_back or try_push_back
f(&v);
// T2: fill the vector with data, but call f after every addition
for (size_t i=0; i<N; ++i) {
v.push_back(data[i]); // or unchecked_push_back or try_push_back
f(&v);
}In T1, an optimizing compiler has enough information to replace the for loop with a bulk update (like a memcpy). In T2 no such optimization is possible because, from the compiler’s perspective, f has the potential to modify v at every iteration.
On my Intel laptop, any differences in speed between the three push_back variations were within the noise:
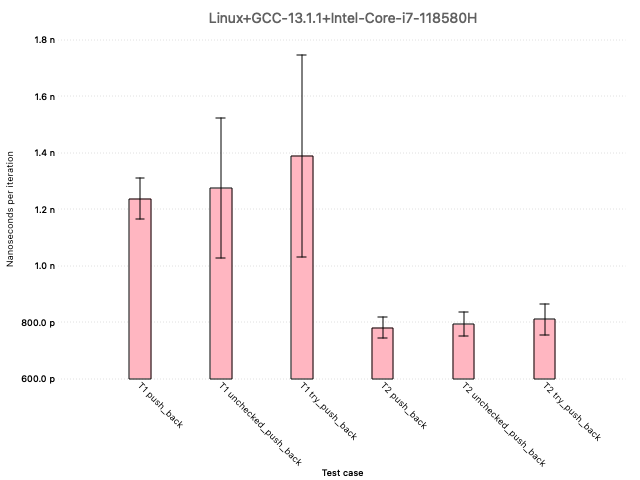
However, the same benchmark run on a Mac Studio M2 produced different results:
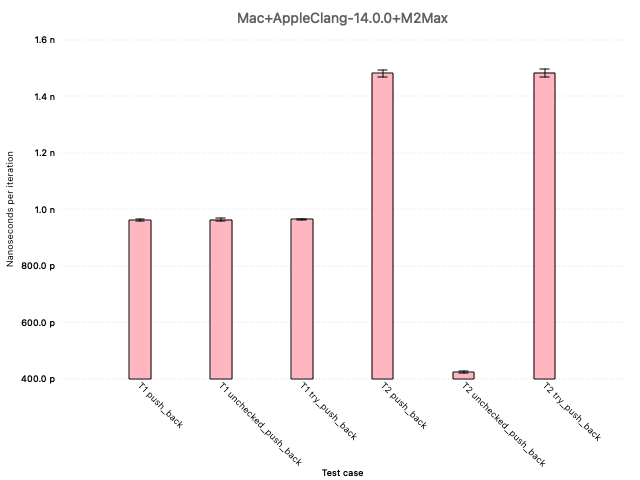
While this hints at a substantial performance benefit for unchecked_push_back on this platform, more analysis is necessary for a definitive conclusion. It is unclear, for example, why unchecked_push_back in T2 is faster than it is in T1.
In my opinion, there isn’t sufficient evidence of a performance benefit to justify unchecked_push_back’s inclusion. The Library Evolution Working Group (LEWG) felt otherwise, so it will be part of what gets standardized.
At any rate, after presented our findings along with the paper at the Varna meeting, LEWG approved the design, and the paper is now headed to the wordsmiths at the Library Working Group (LWG).
Some proposals I’m wary of
Here I’ll discuss three concerning proposals that landed in Varna.
std::function_ref
Vittorio Romeo, Zhihao Yuan, and Jarrad Waterloo authored function_ref. It’s a lightweight type you’d use as a callback parameter:
// Before
void call_n_times( int n, const std::function<void ()> & f );
// After
void call_n_times( int n, std::function_ref<void ()> f );The benefit over std::function is that it can wrap large function objects, such as lambda expressions with many captures, without allocating memory. This parallels how std::string_view parameters avoid allocation when passed string literals.
My concern is that function_ref is easy to misuse and is seldom the best tool for any job.
std::string_view object parameters are temporary in nature, but they can always be converted to std::string objects—which copies the referenced characters—if that data needs to be stored longer. std::function_ref objects can similarly be converted to std::function objects, but because that conversion copies only the source function object—the function_ref—doing so can cause undefined behavior.
Consider this example:
class C {
public:
C( std::function_ref<void ()> f ) : m_f(f) {}
void call() { m_f(); }
private:
std::function<void ()> m_f;
};
void callback() { /*...*/ }
void g() {
C c1( callback ); // Okay. C::C's parameter has a pointer to `callback`.
c1.call(); // Okay. Calls `callback`.
C c2( [](){ callback(); } ); // Uh oh. C::C's parameter has a pointer
// to the temporary lambda object.
c2.call(); // Undefined behavior. c2.m_f tries to use a dangling pointer
// to a temporary.
}We’ll have to train users to avoid creating std::function objects from std::function_ref parameters when the former outlives the latter, but training can only go so far. This kind of defect will unavoidably crop in large code bases.
This leads to my second point, which is that function_ref serves a very narrow use case. Because you cannot generally store function_ref parameters for use later, some of the most common use cases for function parameters (callbacks for asynchronous code, constructors for visitor objects, etc.) can’t use it; function_ref parameters should be limited to functions that call the parameter only in the body of the function.
function_ref even in valid use cases is rarely the right tool. Consider a call_n_times function that calls its parameter n times:
void call_n_times( int n, const std::function<void ()> & f ); // Option 1
void call_n_times( int n, std::invokable<> auto f ); // Option 2
void call_n_times( int n, std::function_ref<void ()> f ); // Option 3If speed is not a concern, all these options suffice. If speed is a concern, option 2 is most viable; you’ll want to eliminate function call overhead by allowing for inlining.
Where does that leave option 3? Well, you may want option 3 if speed is a concern, but not so much of a concern that you want to pay the compilation overhead of option 2. This is a narrow use case.
If std::function_ref only had a narrow use case or only were easy-to-misuse, I might be able to get behind it. However, with both these weaknesses I don’t see it improving the standard library.
std::copyable_function
Michael Florian Hava’s copyable_function proposal introduces std::copyable_function, a class that behaves like std::function, but propagates const and other modifiers to the call operator in a more intuitive and arguably, more correct, way. Its use cases are identical to those of std::function and it is intended to be a wholesale replacement.
While acknowledging the shortcomings of std::function, I think the cost of adding a replacement is too high. Codebases already use std::function prolifically, so users will have to be aware of both types. Additionally, std::function, whose use will now be discouraged, has the better, more intuitive, spelling.
Decisions like this give C++ a deserved reputation of being overly complex and hostile to casual users. Are we next going to introduce an improved std::unordered_map and call it std::bucketless_unordered_map? I can appreciate the tension between maintaining backwards compatibility and making improvements, but sometimes the cure is worse than the disease. I would’ve been much happier if we had accepted std::function as it is, warts and all.
std::bind_{front|back} updates
Those who’ve been in the C++ world for over a decade will remember using Boost.Bind as a clunky way to create anonymous functions before lambda functions became available in C++11. std::bind is in the standard for historical reasons, but lambda functions are preferred for their readability and simplicity. So, why are we making tweaks to the even more esoteric std::bind_front and std::bind_back?
The rationale is:
a) lambdas do not propagate noexcept and constraints, and
b) captures and arguments are not forwarded “easily”.
There’s an element of truth to that, but does this motivation offset the complexity of yet another lambda-like facility in the standard library? I don’t think so. C++ lambda functions are a general-purpose tool that handles these use cases well enough. Engineers can only hold so much in their mental toolbox.
Other notable functionality added to the draft standard
There were a few interesting enhancements to the draft standard in the Varna meeting. The first of these is user-generated static_assert messages.
// Before: static_assert messages limited to string literals
static_assert(size_of(T) <= 32, "T's size must be less than 32 bytes");
// After: static_assert messages can include constexpr evaluated strings
// resulting in improved error messages.
static_assert(size_of(T) <= 32,
std::format("T's size ({}) must be less than 32 bytes", sizeof(T));This is exactly the kind of feature I like; it’s useful and so straightforward users could have assumed it was already there.
I also want to note the additions of RCU and Hazard Pointers to the draft standard. These low-level concurrency mechanisms enable the development of high-performance, thread-safe data structures. I’m eager to get my hands on an implementation and some good tutorials to play with the ideas.
std::variant got a minor update in the form of an ergonomic visit member function.
std::variant</*...*/> x = /*...*/;
// Before: one needs to call the visit free function to perform visitation
std::visit( /*visitor*/, x );
// After: now one can instead use the visit member function
x.visit( /*visitor*/ );Finally submdspan was added to allow for slicing of multidimensional arrays. This operation is especially useful in scientific computing.
Wrapping it up
Congrats if you made it this far! Varna was an exciting meeting and I’m very much looking forward to our other face-to-face meetings this year.

